Sequential LDA
Sentence-level topic modeling
Source:vignettes/pkgdown/sequential.Rmd
sequential.RmdSequential LDA (Latent Dirichlet Allocation) can identify topics of sentences more accurately than the standard LDA, because it considers the topics of the preceding sentence to classify the current sentence. The topics of the preceding sentences not only make the transition of topics smoother but help to mitigate the data sparsity.
Preperation
We use the Sputnik corpus on Ukraine, but preparation in this example
is slightly different from the introduction.
Since Sequential LDA is created for classification of sentences, we
apply corpus_reshape() to the corpus to segment the
texts
library(seededlda)
#> Warning: package 'quanteda' was built under R version 4.3.3
#> Warning in .recacheSubclasses(def@className, def, env): undefined subclass
#> "ndiMatrix" of class "replValueSp"; definition not updated
#> Warning: package 'proxyC' was built under R version 4.3.3
corp <- readRDS("data_corpus_sputnik2022.rds") |>
corpus_reshape(to = "sentences")
toks <- tokens(corp, remove_punct = TRUE, remove_symbols = TRUE,
remove_numbers = TRUE, remove_url = TRUE)
dfmt <- dfm(toks) |>
dfm_remove(stopwords("en")) |>
dfm_remove("*@*") |>
dfm_trim(max_docfreq = 0.1, docfreq_type = "prop")As a result, the DFM has more documents (150925) with sentence number appended to the document names. The sentences make the sparsity of the DFM very high (99.98%).
print(dfmt)
#> Document-feature matrix of: 150,925 documents, 58,961 features (99.98% sparse) and 4 docvars.
#> features
#> docs monday president joe biden reiterated united states commitment
#> s1092644731.1 1 1 1 1 1 1 1 1
#> s1092644731.2 0 0 0 1 0 0 0 0
#> s1092644731.3 0 2 0 1 0 0 0 0
#> s1092644731.4 0 1 0 0 0 0 0 0
#> s1092644731.5 0 0 0 0 0 0 0 0
#> s1092644731.6 0 0 0 0 0 0 0 0
#> features
#> docs diplomacy tensions
#> s1092644731.1 1 1
#> s1092644731.2 1 0
#> s1092644731.3 1 0
#> s1092644731.4 1 0
#> s1092644731.5 0 0
#> s1092644731.6 0 0
#> [ reached max_ndoc ... 150,919 more documents, reached max_nfeat ... 58,951 more features ]Sequential LDA
You can enable the sequential algorithm only by setting
gamma = 0.5. If the value is smaller than this, the topics
of the previous sentence affect less in classifying the current
sentence.
lda_seq <- textmodel_lda(dfmt, k = 10, gamma = 0.5,
batch_size = 0.01, auto_iter = TRUE,
verbose = TRUE)
#> Fitting LDA with 10 topics
#> ...initializing
#> ...using up to 16 threads for distributed computing
#> ......allocating 1510 documents to each thread
#> ...Gibbs sampling in up to 2000 iterations
#> ......iteration 100 elapsed time: 14.36 seconds (delta: 0.27%)
#> ......iteration 200 elapsed time: 27.44 seconds (delta: 0.03%)
#> ......iteration 300 elapsed time: 40.55 seconds (delta: -0.04%)
#> ...computing theta and phi
#> ...complete| topic1 | topic2 | topic3 | topic4 | topic5 | topic6 | topic7 | topic8 | topic9 | topic10 |
|---|---|---|---|---|---|---|---|---|---|
| gas | world | moscow | biden | president | nato | operation | energy | military | ukrainian |
| energy | people | security | discuss | china | finland | military | prices | weapons | sputnik |
| oil | war | foreign | joins | biden | sweden | ukrainian | inflation | ukrainian | media |
| sanctions | discuss | nato | president | taiwan | military | donetsk | uk | nuclear | people |
| european | countries | minister | also | military | security | special | percent | defense | war |
| countries | political | also | former | washington | countries | forces | oil | forces | one |
| eu | joined | countries | sputnik | war | joined | republics | government | kiev | also |
| prices | international | military | get | also | alliance | donbass | year | also | photo |
| europe | sean | united | house | nato | hour | lugansk | crisis | ministry | military |
| also | jacquie | president | new | security | turkey | february | price | according | kiev |
Seeded Sequential LDA
You can also enable the sequential algorithm in Seeded LDA only by setting
gamma > 0.
dict <- dictionary(file = "dictionary.yml")
print(dict)
#> Dictionary object with 5 key entries.
#> - [economy]:
#> - market*, money, bank*, stock*, bond*, industry, company, shop*
#> - [politics]:
#> - parliament*, congress*, white house, party leader*, party member*, voter*, lawmaker*, politician*
#> - [society]:
#> - police, prison*, school*, hospital*
#> - [diplomacy]:
#> - ambassador*, diplomat*, embassy, treaty
#> - [military]:
#> - military, soldier*, terrorist*, air force, marine, navy, army
lda_seed <- textmodel_seededlda(dfmt, dict, residual = 2, gamma = 0.5,
batch_size = 0.01, auto_iter = TRUE,
verbose = TRUE)
#> Fitting LDA with 7 topics
#> ...initializing
#> ...using up to 16 threads for distributed computing
#> ......allocating 1510 documents to each thread
#> ...Gibbs sampling in up to 2000 iterations
#> ......iteration 100 elapsed time: 12.70 seconds (delta: 0.05%)
#> ......iteration 200 elapsed time: 24.17 seconds (delta: -0.01%)
#> ...computing theta and phi
#> ...complete| economy | politics | society | diplomacy | military | other1 | other2 |
|---|---|---|---|---|---|---|
| energy | biden | ukrainian | nato | military | china | nato |
| gas | discuss | people | security | ukrainian | countries | sputnik |
| oil | president | police | moscow | operation | also | eu |
| prices | joins | one | military | forces | world | european |
| sanctions | also | war | president | special | india | finland |
| market | congress | also | ukrainian | donetsk | president | countries |
| countries | sputnik | minister | foreign | kiev | new | sweden |
| price | political | sputnik | weapons | republics | economic | also |
| inflation | get | photo | states | donbass | international | media |
| european | joined | johnson | united | lugansk | foreign | military |
The plot show the topic probability of the first 100 sentences from an article in the corpus. Thanks to the sequential algorithm, adjacent sentences are classified into the same topics.
ggmatplot(lda_seed$theta[paste0("s1104078647.", 1:100),],
plot_type = "line", linetype = 1,
xlab = "Sentence", ylab = "Probability", legend_title = "Topic")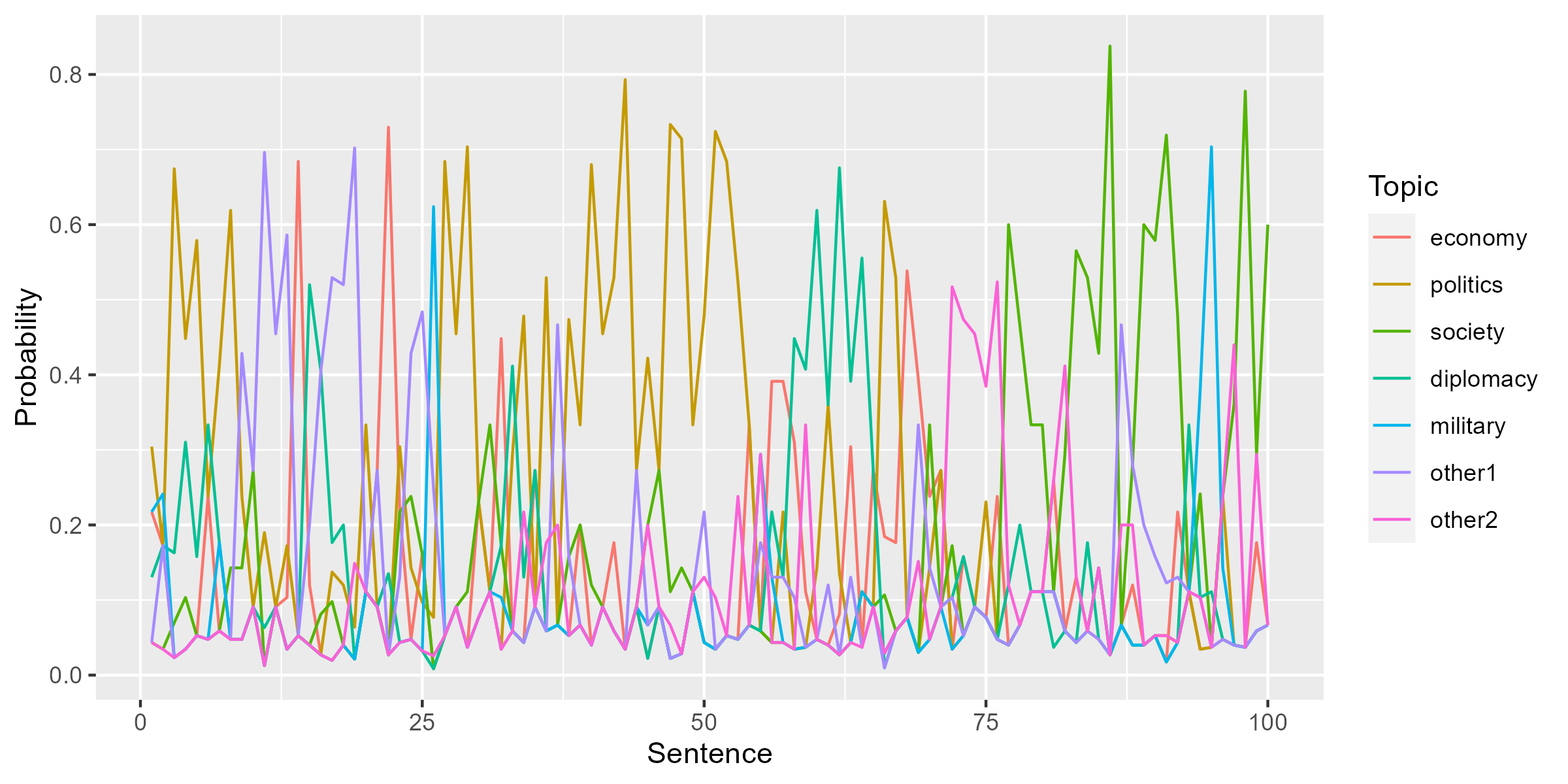
References
- Du, L., Buntine, W., Jin, H., & Chen, C. (2012). Sequential latent Dirichlet allocation. Knowledge and Information Systems, 31(3), 475–503. https://doi.org/10.1007/s10115-011-0425-1
- Watanabe, K., & Baturo, A. (2023). Seeded Sequential LDA: A Semi-Supervised Algorithm for Topic-Specific Analysis of Sentences. Social Science Computer Review. https://doi.org/10.1177/08944393231178605